This is the first article in the series “Developing our programming language in Java” which is aimed to show the full path of creating a language, as well as writing and maintaining tools for it. By the end of this article, we will implement an interpreter with which it will be possible to execute programs in our language. Any programming language has a syntax that needs to be converted into a data structure that is convenient for validation, transformation and execution. As a rule, such a data structure is an abstract syntax tree (AST). Each tree node represents a construct that occurs in the source code. The source code is parsed by the parser, and the output is AST.
Languages have been developed for a long time, and therefore at the moment we have quite a few mature tools, including parser generators. Parser generators take a description of the grammar of a particular language as input, and as output we get parsers, interpreters and compilers.
In this article, we will consider the ANTLR tool. ANTLR is a utility that receives a grammar in the form EBNF as input, and interfaces/classes as output (in our case, this is java code) for parsing programs. The list of languages in which parsers are generated can be found here.
Grammar example
Before moving on to real grammar, let’s try to describe some of the rules of a typical programming language in words:
VARIABLEis anIDENTIFIERDIGITis one of the characters0123456789NUMBERis one or more elements of typeDIGITEXPRESSIONisNUMBEREXPRESSIONisVARIABLEEXPRESSIONisEXPRESSION‘+’EXPRESSIONEXPRESSIONis ‘(‘EXPRESSION’)’
As you can see from this list, a language grammar is a set of rules that can have recursive links. Each rule can refer to itself or to any other rule. ANTLR has many operators in its arsenal to describe such rules.
: marker of the beginning of the rule
; rule end marker
| alternative operator
.. range operator
~ denial
. any character
= assignment
(...) sub-rule
(...)* repeating of a subrule 0 or more times
(...)+ repeating of a subrule 1 or more times
(...)? subrule, may be missing
{...} semantic actions (in the language used as the output - for example, Java)
[...] rule parameters
ANTLR rule examples
The following example describes the rules for integers and floating-point numbers:
NUMBER : [0-9]+ ; FLOAT : NUMBER '.' NUMBER ;
It is very important to understand that the grammar describes only the syntax of the language on the basis of which the parser will be generated. The parser will generate an AST, with which help it will be possible to implement the semantics of the language. In the previous example, we set a rule for parsing an integer, but did not describe how much memory the number occupies (8 bits, 16, …), and whether the number is signed or unsigned. For example, in some programming languages you can start using a variable without declaring it. You can also not declare the type of the variable; in this case the type will be determined automatically at runtime. All these rules of language semantics are not described in the grammar, but are implemented in another part of the language.
ANTLR tokens and expressions
ANTLR grammar consists of two types of rules: tokens and expressions, which are used to define the structure of the grammar and parse input.
Tokens are rules that define individual lexical elements of the input language, such as numbers, identifiers, operation signs, and so on. Each token corresponds to a certain type of token, which is used for further processing by the parser. The lexical analyzer scans the input text, parses it into tokens, and creates a sequence of tokens, which are then passed to the parser. They are written in uppercase (For example: NUMBER, IDENTIFIER).
Expressions are rules that define the grammar structure of the input language. They describe how tokens are related and how they can be combined into more complex structures. Expressions can contain references to tokens as well as to other expressions. Written in camelCase notation (For example: expression, functionDefinition).
Thus, the difference between tokens and expressions in ANTLR is that tokens define individual lexical elements of the input language and convert them into tokens, while expressions define the structure of the grammar and describe how tokens are related to each other in more complex structures.
Language Requirements
Before you start implementing a language, you need to determine the set of features it should support. For our task, for educational purposes, we will use a simple grammar. The language will support the following constructs:
- Variables (types
String,Long,Double); - Assignment operator (=);
- Arithmetic operations (+, -, *, /);
- Comparison operators (>, <, >=, <=, ==, !=);
- Conditional statements (if , else);
- Functions;
- Print to the console (built-in
printlnoperator).
Grammar
And finally, a complete description of the grammar for the language:
grammar Jimple ;
// root rule of grammar
program: (statement)* EOF;
// list of possible statements
statement: variableDeclaration
| assignment
| functionDefinition
| functionCall
| println
| return
| ifStatement
| blockStatement
;
// list of possible expressions
expression: '(' expression ')' #parenthesisExpr
| left=expression op=(ASTERISK | SLASH) right=expression #mulDivExpr
| left=expression op=(PLUS | MINUS) right=expression #plusMinusExpr
| left=expression compOperator right=expression #compExpr
| IDENTIFIER #idExp
| NUMBER #numExpr
| DOUBLE_NUMBER #doubleExpr
| STRING_LITERAL #stringExpr
| functionCall #funcCallExpr
;
// descriptions of individual expressions and statements
variableDeclaration: 'var' IDENTIFIER '=' expression ;
assignment: IDENTIFIER '=' expression ;
compOperator: op=(LESS | LESS_OR_EQUAL | EQUAL | NOT_EQUAL | GREATER | GREATER_OR_EQUAL) ;
println: 'println' expression ;
return: 'return' expression ;
blockStatement: '{' (statement)* '}' ;
functionCall: IDENTIFIER '(' (expression (',' expression)*)? ')' ;
functionDefinition: 'fun' name=IDENTIFIER '(' (IDENTIFIER (',' IDENTIFIER)*)? ')' '{' (statement)* '}' ;
ifStatement: 'if' '(' expression ')' statement elseStatement? ;
elseStatement: 'else' statement ;
// list of tokens
IDENTIFIER : [a-zA-Z_] [a-zA-Z_0-9]* ;
NUMBER : [0-9]+ ;
DOUBLE_NUMBER : NUMBER '.' NUMBER ;
STRING_LITERAL : '"' (~["])* '"' ;
ASTERISK : '*' ;
SLASH : '/' ;
PLUS : '+' ;
MINUS : '-' ;
ASSIGN : '=' ;
EQUAL : '==' ;
NOT_EQUAL : '!=' ;
LESS : '<' ;
LESS_OR_EQUAL : '<=' ;
GREATER : '>' ;
GREATER_OR_EQUAL : '>=' ;
SPACE : [ \r\n\t]+ -> skip;
LINE_COMMENT : '//' ~[\n\r]* -> skip;
As you have probably already guessed, our language is called Jimple (derived from Jvm simple). It’s probably worth explaining some points that may not be obvious when you first get acquainted with ANTLR.
Labels
op label has been used to describe the rules for some operations. This allows us to use this label later as the name of a variable that will contain the value of the operator. Theoretically, we could avoid specifying labels, but in this case, we would have to write additional code to get the value of the operator from the parse tree.
compOperator: op=(LESS | LESS_OR_EQUAL | EQUAL | NOT_EQUAL | GREATER | GREATER_OR_EQUAL) ;
Named rule alternatives
In ANTLR, by defining a rule with multiple alternatives, a user can assign a name to every of them, and then in the tree it will appear in a form of a separate processing node. That is very convenient when you need to assign to the processing of every rule option a separate method. It is important that the names must be given either to all alternatives or to none of them. The following example demonstrates what it looks like:
expression: '(' expression ')' #parenthesisExpr
| IDENTIFIER #idExp
| NUMBER #numExpr
ANTLR will generate the following code:
public interface JimpleVisitor<T> {
T visitParenthesisExpr(ParenthesisExprContext ctx);
T visitIdExp(IdExpContext ctx);
T visitNumExpr(NumExprContext ctx);
}
Channels
ANTLR has such a construct as channels. Usually, channels are used to work with comments, but since in most cases we do not need to check for comments, they must be discarded with -> skip, that we have already used. However, there are cases when we need to interpret the meaning of comments or other constructs, in this case you should use pipes. ANTLR has already a built-in channel called HIDDEN that you can use, or you can also declare your own channels for specific purposes. Later, by parsing the code, you will be able to access these channels.
An example of declaring and using a channel
channels { MYLINECOMMENT }
LINE_COMMENT : '//' ~[rn]+ -> channel(MYLINECOMMENT) ;
Fragments
Along with tokens, ANTLR has such an element as fragments. Rules with a fragment prefix can only be called from other lexer rules. They are not tokens per se. In the following example, we moved the definitions of numbers for different number systems into fragments.
NUMBER: DIGITS | OCTAL_DIGITS | HEX_DIGITS;
fragment DIGITS: '1'..'9' '0'..'9'*;
fragment OCTAL_DIGITS: '0' '0'..'7'+;
fragment HEX_DIGITS: '0x' ('0'..'9' | 'a'..'f' | 'A'..'F')+;
Thus, a number in any number system (for example: “123”, “0762”, or “0xac1”) will be treated as a NUMBER token, not DIGITS, OCTAL_DIGITS, or HEX_DIGITS. Jimple does not use fragments.
Tools
Before we start generating the parser, we need to set up the tools to work with ANTLR. As is known, a good and convenient tool makes half the success. To accomplish that, we need to download ANTLR library and to write scripts in order to run it. There are also maven/gradle/IntelliJ IDEA plugins, which we will not be using in this article, but for productive development, they can be found useful.
We need the following scripts:
antlr4.sh script
java -Xmx500M -cp ".:/usr/lib/antlr-4.12.0-complete.jar" org.antlr.v4.Tool $@
grun.sh script
java -Xmx500M -cp ".:/usr/lib/antlr-4.12.0-complete.jar" org.antlr.v4.gui.TestRig $@
Parser generation
Save the grammar in the file Jimple.g4. Next, run the script like this:
antlr4.sh Jimple.g4 -package org.jimple.lang -visitor
-package option allows you to specify the java package in which the code will be generated. The -visitor option allows you to generate a JimpleVisitor interface that implements the Visitor pattern.
After successful execution of the script, several files will appear in the current directory: JimpleParser.java, JimpleLexer.java, JimpleListener.java, JimpleVisitor.java. The first two files contain the generated parser and lexer code, respectively. The other two files contain interfaces for working with the parse tree. In this article, we will use the JimpleVisitor interface, more specifically JimpleBaseVisitor — this one is also a generated class that implements the JimpleVisitor interface and contains implementations of all methods. It allows us to override only the methods we need.
Interpreter Implementation
Finally, we have reached the most interesting part — the implementation of the interpreter. Although in this article we will not analyze the issue of checking the code for errors, some interpretation errors will still be implemented. First of all, let’s create a JimpleInterpreter class with an eval method, which will take a string with the code for Jimple as input. Next, we need to parse the source code into tokens using JimpleLexer, then to create an AST tree using JimpleParser.
public class JimpleInterpreter {
public Object eval(final String input) {
// parse initial code on tokens
final JimpleLexer lexer = new JimpleLexer(CharStreams.fromString(input));
// create AST tree
final JimpleParser parser = new JimpleParser(new CommonTokenStream(lexer));
// create an object class JimpleInterpreterVisitor
final JimpleInterpreterVisitor interpreterVisitor = new JimpleInterpreterVisitor(new JimpleContextImpl(stdout));
// run interpreter
return interpreterVisitor.visitProgram(parser.program());
}
}
We have a syntax tree. Let’s add semantics with the JimpleInterpreterVisitor class we wrote, which will bypass the AST by calling up the appropriate methods. Since the root rule of our grammar is the program rule (see program: (statement)* EOF above), the tree traversal starts from it. To accomplish this, we call the visitProgram method implemented by default on the JimpleInterpreterVisitor object, to the input of which we give an object of the ProgramContext class. The ANTLR implementation consists of calling the visitChildren (RuleNode node) that traverses all the descendant items of the given tree node, calling the visit method on each of them.
// code generated by ANTLR
public class JimpleBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements JimpleVisitor<T> {
@Override
public T visitProgram(JimpleParser.ProgramContext ctx) {
return visitChildren(ctx);
}
// other methods omitted for brevity
}
As you can see, JimpleBaseVisitor is a generic class for which you need to define the type of processing for each node. In our case, this is the Object class, since expressions can return values of different types. Typically, an expression must return a value, while a statement returns nothing – this is their difference. In case of statement, we can return null. However, in order not to accidentally encounter NullPointerException, instead of null we will return an object of type Object, which is globally defined in the JimpleInterpreter class:
public static final Object VOID = new Object();
JimpleInterpreterVisitor class extends class JimpleBaseVisitor, overriding only the methods we are interested in. Let’s consider the implementation of the built-in println operator, which is described in the grammar as println: 'println' expression ;. The first thing we need to complete is to evaluate the expression, for this we need to call the visit method and pass the expression object from the current PrintlnContext into it. In the visitPrintln method, we are absolutely not interested in a calculation process of an expression; the corresponding method is responsible for calculating each rule (context). For example, the visitStringExpr method is used to evaluate a string literal.
public class JimpleInterpreterVisitor extends JimpleBaseVisitor<Object> {
@Override
public Object visitPrintln(final JimpleParser.PrintlnContext ctx) {
final Object result = visit(ctx.expression());
System.out.println(result);
return VOID;
}
@Override
public Object visitStringExpr(final JimpleParser.StringExprContext ctx) {
// return string literal
return cleanStringLiteral(ctx.STRING_LITERAL().getText());
}
private String cleanStringLiteral(final String literal) {
// clear string from quotation marks
return literal.length() > 1 ? literal.substring(1, literal.length() - 1) : literal;
}
// other methods omitted for brevity
}
By implementing only these methods, the interpreter already supports println and string literals, which allows us to execute println "Hello, Jimple!" code.
Run interpreter
To launch the interpreter, you need to create a standard main method, which after some small checks with the use of the JimpleInterpreter class, will run our code:
public class MainApp {
public static void main(String[] args) {
if (args.length < 1) {
System.out.println("usage: jimple input.jimple");
System.exit(1);
}
Path path = Paths.get(args[0]);
if (!Files.exists(path)) {
System.err.println("File not found: " + path);
System.exit(1);
}
new JimpleInterpreter().eval(path);
}
}
Implementation details
There is no need to provide the entire implementation code of the interpreter, a link to the source code can be found at the end of the article. However, I want to examine some interesting details.
As already mentioned, the interpreter is based on the Visitor pattern, which visits the nodes of the AST tree and executes the corresponding instructions. In the process of code execution in the current context it appears that new identifiers (names of variables and/or functions) need to be stored somewhere. To do this, we will write a JimpleContext class that will store not only these identifiers, but also the current context for executing nested code blocks and functions, since a local variable and/or function parameter must be deleted after leaving their scope.
@Override
public Object handleFunc(FunctionSignature func, List<String> parameters, List<Object> arguments, FunctionDefinitionContext ctx) {
Map<String, Object> variables = new HashMap<>(parameters.size());
for (int i = 0; i < parameters.size(); i++) {
variables.put(parameters.get(i), arguments.get(i));
}
// create a new function scope and push it onto the stack
context.pushCallScope(variables);
// execution of function expressions omitted for brevity
// remove the scope of function parameters from the stack
context.popCallScope();
return functionResult;
}
In our language, a variable stores a value of a type that is determined at runtime. Further, in the following instructions, this type may change. Thus, we got a dynamically typed language. However, some checking of types is still present in cases where performing the operation is pointless. For example, a number cannot be divided by a string.
Why do we need two passes?
The original version of the interpreter was to implement a method for each rule. For example, if a function declaration processing method finds a function with the same name (and number of parameters) in the current context, then an exception is thrown, otherwise the function is added to the current context. The function call method works the same way. If the function is not found, then an exception is thrown, otherwise the function is called. This approach works, but it does not allow you to call the function before it is defined. For example, the following code will not work:
var result = 9 + 10
println "Result is " + add(result, 34)
fun add(a, b) {
return a + b
}
In this case, we have two approaches. The first one is to require functions to be defined before they are used (not very convenient for users of the language). The second approach is to perform two passes. The first pass is needed for finding out all the functions that have been defined in the code. And the second is directly for executing the code. In my implementation, I chose the second approach. The implementation of the visitFunctionDefinition method should be moved to a separate class that extends the generated class JimpleBaseVisitor<T> that is already known to us.
// class finds all functions in the code and registers them in the context
public class FunctionDefinitionVisitor extends JimpleBaseVisitor<Object> {
private JimpleContext context;
private FunctionCallHandler handler;
public FunctionDefinitionVisitor(JimpleContext context, FunctionCallHandler handler) {
this.context = context;
this.handler = handler;
}
@Override
public Object visitFunctionDefinition(JimpleParser.FunctionDefinitionContext ctx) {
String name = ctx.name.getText();
List<String> parameters = ctx.IDENTIFIER().stream().skip(1).map(ParseTree::getText).toList();
var funcSig = new FunctionSignature(name, parameters.size());
context.registerFunction(funcSig, (func, args) -> handler.handleFunc(func, parameters, args, ctx));
return VOID;
}
}
Now we have a class that we can use before executing the interpreter class directly. It will fill our context with the definitions of all the functions that we will call in the interpreter class.
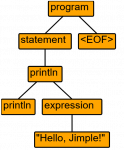
What does an AST look like?
In order to visualize the AST, you need to use the grun utility (see above). To do this, run grun with the parameters Jimple program -gui (the first parameter is the name of the grammar, the second is the name of the rule). As a result, a window with the AST tree will be opened. Before executing this utility, it is important to compile the code generated by ANTLR.
# generate a parser antlr4.sh Jimple.g4 # compile the generated code javac -cp ".:/usr/lib/jvm/antlr-4.12.0-complete.jar" Jimple*.java # run grun grun.sh Jimple program -gui # enter code: `println "Hello, Jimple!"` # press Ctrl+D (Linux) or Ctrl+Z (Windows)
For the Jimple code println "Hello, Jimple!", the following AST will be generated:
Summary
In this article you have got acquainted with such concepts as lexical and parser analyzers. We used the ANTLR tool to generate such analyzers. You have also learned how to write ANTLR grammar. As a result, we created a simple language, namely, developed an interpreter for it. As a bonus, we managed to visualize the AST.
The entire source code of the interpreter can be viewed by link.
Links
- https://www.antlr.org/
- https://en.wikipedia.org/wiki/Abstract_syntax_tree
- https://en.wikipedia.org/wiki/Compiler-compiler